Jeden Tag begegnen wir neuen Schlagzeilen über Künstliche Intelligenz. Die Diskussionen bewegen sich oft zwischen Faszination und Furcht: Kann eine KI wirklich denken? Versteht sie, was sie schreibt? Wo liegen ihre Grenzen, und wo wird sie uns Menschen überflügeln? Eine der drängendsten Fragen unserer Zeit ist zweifellos, ob KI Arbeitsplätze vernichten wird oder ob wir vor einer Transformation stehen, in der sich Aufgabenbereiche lediglich verschieben.
Um solche Fragen fundiert zu beantworten, reicht es nicht, Meinungen oder Science-Fiction zu folgen. Man muss verstehen, wie diese Systeme im Inneren funktionieren.
Diese Artikel-Reihe schließt die Lücke zwischen oberflächlichen Technologie-News und akademischer Fachliteratur. Sie richtet sich an alle, die nachvollziehen möchten, wie generative KI tatsächlich arbeitet – ohne Vorkenntnisse im Machine Learning, jedoch mit der Bereitschaft, analytisch hinter die Benutzeroberfläche zu blicken.
Fokus, Methodik und Abgrenzung
Die Artikel dieser Serie konzentrieren sich bewusst auf transformerbasierte Sprachmodelle – die heute dominante Architektur hinter ChatGPT, Claude und ähnlichen Systemen. Andere Forschungsrichtungen (symbolische KI, hybride Architekturen) sind ebenso relevant, würden hier jedoch vom Ziel ablenken: dem mechanischen Verständnis, wie diese Modelle intern Informationen verarbeiten.
Die zugrunde liegende Theorie – von der Transformer-Architektur (vgl. Vaswani et al., 2017)[1] bis zu GPT-3 (vgl. Brown et al., 2020)[2] – ist jedoch häufig abstrakt und mathematisch komplex. Die Serie entspringt daher einer doppelten Motivation: wissenschaftliche Neugier (Was passiert zwischen Eingabe und Antwort?) und die Überzeugung, dass nur technisches Verständnis zu realistischen Einschätzungen führt. Wer weiß, dass eine KI Wahrscheinlichkeiten berechnet, statt im menschlichen Sinne zu „denken“, kann besser beurteilen, wo sie unterstützen kann und wo sie scheitern muss.
Um die Lücke zwischen Theorie und intuitivem Verständnis zu schließen, habe ich den LLM Explorer entwickelt – ein didaktisches Experiment, das verborgene Rechenschritte in manipulierbare Parameter übersetzt. Man kann nicht nur beobachten, was das Modell tut, sondern warum es unter geänderten Bedingungen anders entscheidet. Diese Methode des “experimentellen Verstehens” unterscheidet sich grundlegend von passiven Erklärvideos und wird uns durch die gesamte Serie begleiten.
1. Die Anatomie der Verarbeitung: Ein Phasen-Modell
Um die Funktionsweise eines LLMs zu verstehen, darf man es nicht als monolithischen “Gehirn”-Block betrachten. Mein persönlicher Ansatz, um diese “Black Box” zu durchdringen, orientierte sich am klassischen EVA-Prinzip der Informatik: Eingabe, Verarbeitung, Ausgabe. Die zentrale Frage lautete: Was genau geschieht Schritt für Schritt mit meinen Daten bzw. meinem Prompt, nachdem ich Enter drücke und bevor der erste Buchstabe der Antwort erscheint?
Bei dem Versuch, diese Verarbeitungskette wissenschaftlich nachzuvollziehen und in ihre Einzelteile zu zerlegen, kristallisierte sich auf Basis der relevanten Literatur (u.a. Vaswani et al., 2017; Mikolov et al., 2013)[1][3] eine Architektur heraus, die sich gut in fünf aufeinander aufbauenden Phasen darstellen lässt:
- Phase 0 (Der Input): Die Übersetzung von Sprache in Mathematik (Tokenization).
- Phase 1 (Der Raum): Wie Wörter Bedeutung und Position erhalten (Embedding & Positional Encoding).
- Phase 2 (Der Fokus): Wie Zusammenhänge und Kontext erkannt werden (Attention Mechanism).
- Phase 3 (Das Wissen): Wo Fakten und Konzepte verarbeitet werden (Feed Forward Networks).
- Phase 4 (Der Output): Wie aus Wahrscheinlichkeiten wieder Text wird (Decoding & Sampling).
Alle fünf Phasen werden wir uns im weiteren Verlauf der Artikelserie genauer anschauen.
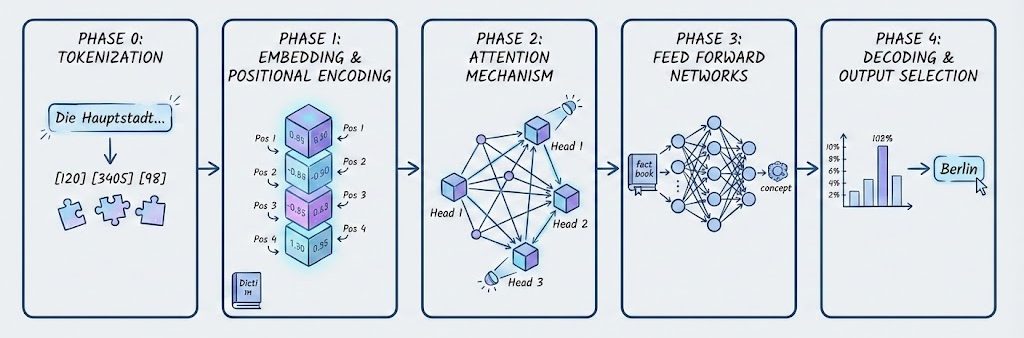
Bevor man jedoch in die mathematische Tiefe dieser Phasen abtaucht, sollte ein Bewusstsein dafür geschaffen werden, mit welchen linguistischen Problemen ein solches System überhaupt zu kämpfen hat.
2. Die wissenschaftliche Herausforderung: Zwei Szenarien
Ein LLM mit trivialen Eingaben wie “Hallo” zu testen, liefert wenig Erkenntnisse über dessen interne Mechanik. Um die Grenzen und Fähigkeiten der Transformer-Architektur zu verstehen, benötigt man “Stress-Tests” – linguistische Konstruktionen, die das Modell zwingen, komplexe Entscheidungen zu treffen.
Im Rahmen der Recherche wurden zwei spezifische Szenarien betrachtet, die exemplarisch für zwei große Herausforderungen der maschinellen Sprachverarbeitung stehen und im Folgenden immer wieder als Grundlage dienen: Ambiguität der Absicht und Polysemie. Wir werden im Verlauf der Serie sehen, dass diese auf den ersten Blick harmlosen Beispiele eine enorme interne Komplexität aufweisen, die die Verarbeitung für die Maschine zu einer echten Herausforderung macht.
2.1 Szenario A: Der “Kontext-Mixer” (Ambiguität der Absicht)
Das erste Beispiel wirkt zunächst sehr simpel, offenbart aber bei genauerer Betrachtung die Komplexität der Kontext-Steuerung.
Der Prompt:
“Die Hauptstadt von Deutschland ist”
Die wissenschaftliche Fragestellung:
Intuitiv ist die Antwort klar: “Berlin”. Doch technisch betrachtet ist ein Sprachmodell kein Lexikon. Es ist eine Maschine, die Wahrscheinlichkeiten berechnet. Die zentrale Erkenntnis dabei ist: Die Wahrscheinlichkeit für das nächste Wort ergibt sich direkt aus dem Kontext der vorangegangenen Wörter.
Aber wie genau funktioniert diese Ableitung? Wie wird aus dem Kontext plötzlich die Antwort „schön“ statt „Berlin“?
An dieser Stelle passiert etwas Entscheidendes: Der Satz wird im Modell nicht nur „gelesen“, sondern seine Bestandteile werden unterschiedlich stark miteinander in Beziehung gesetzt. Dafür nutzt das Modell sogenannte Attention Heads – darauf werden wir später noch im Detail eingehen. Man kann sie sich vereinfacht wie mehrere Scheinwerfer vorstellen. Jeder von ihnen „schaut“ auf andere Teile des Satzes und gewichtet sie unterschiedlich stark. Dadurch verändert sich, welche Informationen für die weitere Verarbeitung besonders wichtig werden. Das führt dazu, dass das interne Bedeutungsbild des Satzes leicht anders aussieht – und genau diese veränderte Repräsentation ist die Grundlage dafür, welches Wort am Ende als wahrscheinlichste Fortsetzung berechnet wird.
Simulation vs. Realität: Hier bietet der LLM Explorer einen entscheidenden Vorteil für das Verständnis: Wir können den Fokus dieser Scheinwerfer manuell auf einzelne Wörter (Tokens) lenken und so den Kontext und damit einhergehend auch den Ausgang manipulieren – wir zwingen das Modell quasi, historisch zu denken. In einem echten LLM hingegen werden diese Heads automatisch durch den Kontext gesteuert. Das Wort “Die” zieht die Aufmerksamkeit des “Historien-Heads” an, während das Wort “Deutschland” den “Fakten-Head” aktiviert. Fehlt ein solcher Kontext-Trigger, dann greift das Modell auf die statistische Basis zurück. Ohne weitere Hinweise gewinnt dann einfach die Antwort mit der höchsten Trainingshäufigkeit: wir landen wieder bei “Berlin”.
In der Simulation wird sichtbar, wie fünf konkurrierende Pfade latent vorhanden sind, bevor diese Entscheidung fällt:
- Fokus auf “Deutschland” (Faktische Logik):
- Der Mechanismus: Ein Head richtet seine Aufmerksamkeit auf das Kern-Subjekt “Deutschland”.
- Die Folge: Dies aktiviert das Faktenwissen im neuronalen Netz.
- Das Ergebnis: Die Wahrscheinlichkeit für “Berlin” steigt massiv an.
- Fokus auf “Die” (Historischer Kontext):
- Der Mechanismus: Ein anderer Head konzentriert sich auf den Artikel “Die” am Satzanfang.
- Die Folge: Dies aktiviert Muster für narrative Erzählungen oder historische Rückblicke (der “Schmetterlingseffekt” eines unscheinbaren Startwortes).
- Das Ergebnis: Der Kontext verschiebt sich Richtung Vergangenheit, die Wahrscheinlichkeit für “Bonn” steigt.
- Fokus auf “Hauptstadt” (Ästhetik):
- Der Mechanismus: Der Fokus liegt auf der qualitativen Bedeutung des Wortes.
- Das Ergebnis: Es wird nach einem Adjektiv gesucht ➜ “schön”.
- Fokus auf “ist” (Wahrnehmung):
- Der Mechanismus: Der Fokus liegt auf dem Zustandsverb.
- Das Ergebnis: Es wird eine Zustandsbeschreibung erwartet ➜ “laut”.
- Fokus auf “von” (Relation):
- Der Mechanismus: Der Fokus liegt auf der Präposition.
- Das Ergebnis: Es wird eine räumliche Distanz berechnet ➜ “weit weg”.
Das Szenario ist auch im LLM Explorer unter der Bezeichnung “Hauptstadt: Der Kontext-Mixer” verfügbar.
2.2 Szenario B: Die dreifache Bank (Polysemie)
Während das erste Szenario die Absicht prüft, widmet sich das zweite dem härtesten Problem der Semantik: der Mehrdeutigkeit von Wörtern (Polysemie).
Der Prompt:
“Der Bankräuber sitzt auf einer Bank vor der Bank.”
Die wissenschaftliche Fragestellung:
Für einen Menschen ist dieser Satz sofort verständlich. Ein Computer sieht zunächst jedoch nur Zeichenketten. Das Wort “Bank” taucht dreimal auf und ist orthografisch identisch:
- Bank (1): In “Bankräuber” ➜ Finanzinstitut/Tatort.
- Bank (2): In “auf einer Bank” ➜ Sitzgelegenheit.
- Bank (3): In “vor der Bank” ➜ Gebäude.
Frühere Sprachmodelle (wie Word2Vec, Mikolov et al.)[3] scheiterten oft an solchen Sätzen, da sie dem Wort “Bank” nur einen festen Vektor zuweisen konnten. Ein moderner Transformer muss jedoch dynamisch erkennen, dass:
- das Wort “Räuber” die Bedeutung der ersten Bank verändert.
- die Präposition “auf” die zweite Bank mit sehr hoher Wahrscheinlichkeit zu einem Möbelstück macht.
- (Wichtige Nuance: Dies ist nicht zwingend und grundsätzlich so. Würde im Satz statt “Räuber” ein “Dachdecker” stehen, könnte “auf der Bank” bedeuten, dass er auf dem Dach des Gebäudes arbeitet. Das Modell muss also nicht nur das direkte Nachbarwort (“auf”), sondern den globalen Kontext (“Räuber” vs. “Dachdecker”) berücksichtigen, um die Bedeutung korrekt zu justieren.)
Wie schafft es ein mathematisches Modell, demselben Wort drei völlig unterschiedliche Bedeutungen zuzuweisen, basierend auf Wörtern, die weit entfernt im Satz stehen?
2.3 Reality Check: Die Diktatur der Wahrscheinlichkeit
Die Analyse der beiden zuvor beschriebenen Szenarien führt zu einer entscheidenden Erkenntnis: Ein LLM verfügt intern über ein breites Spektrum an möglichen Fortsetzungen (“Bonn”, “schön”, “Finanzinstitut”), die alle gleichzeitig als latente Pfade existieren.
In der Praxis (z.B. bei der Nutzung von ChatGPT) bleiben diese Alternativen jedoch oft unsichtbar. Der Grund ist die statistische Dominanz der Trainingsdaten: Da “Hauptstadt” in den Daten millionenfach häufiger mit “Berlin” korreliert als mit “schön”, unterdrücken die extrem starken Gewichte des “Fakten-Heads” alle anderen Signale. Das Modell wirkt deterministisch und entscheidet sich für den “Mainstream”.
Hier liegt der wissenschaftliche Mehrwert des LLM Explorers: Er erlaubt uns, diese statistische “Diktatur der Wahrscheinlichkeit” künstlich aufzubrechen. Indem wir die dominanten Heads dämpfen, machen wir die schwächeren, aber vorhandenen Assoziationen sichtbar. Wir simulieren damit manuell jenen Zustand, der in einem echten Dialog durch Kontext entstünde. Hätte man im Chat zuvor über die 1980er Jahre diskutiert, würde das Modell automatisch den “Historien-Head” priorisieren und “Bonn” wählen. Im LLM Explorer machen wir diese latenten Pfade sichtbar, die sonst nur durch starken Kontextbezug, hohe Kreativitätseinstellungen (“Temperature”) oder eben durch Fehlfunktionen (Halluzinationen) zum Vorschein kämen. Dies entspricht einem Paradigma, das aus den Naturwissenschaften bekannt ist: Das Unsichtbare durch kontrollierte Störung sichtbar machen. So wie ein Physiker die Eigenschaften eines Teilchens durch Streuexperimente erforscht, machen wir die verborgenen Mechanismen eines LLMs durch gezielte Parametervariation beobachtbar. Der Explorer ist damit nicht nur ein Lernwerkzeug, sondern eine experimentelle Methode zur Erforschung emergenten Verhaltens in neuronalen Netzen.
3. Das Werkzeug: Eine kurze Einführung in den LLM Explorer
Damit die theoretischen Konzepte in den kommenden Artikeln nachvollziehbar bleiben, folgt hier eine kurze Übersicht zur Bedienung unserer Simulationsumgebung. Der LLM Explorer dient als “Sandbox”, in der man die internen Zustände des Modells beliebig manipulieren kann.
3.1 Szenario-Auswahl
Der Einstieg erfolgt über die Szenario-Kacheln im Start-Bildschirm des LLM-Explorers. Hinter den Kacheln verbergen sich die vorbereiteten Experimente (wie die im vorangehenden Abschnitt beschriebenen Szenarien “Hauptstadt” und “Bank”). Ein Klick auf eine Kachel lädt den entsprechenden Satz und initialisiert alle neuronalen Gewichte neu.
3.2 Die interaktive Steuerung
Der Explorer ist in die oben beschriebenen Phasen (Tabs) unterteilt. In jeder Phase finden sich interaktive Regler, mit denen man die Berechnungen des Modells beeinflussen kann.

Das Ziel ist es, in jeder Phase zu experimentieren: Was passiert mit der “Bank”, wenn man das Rauschen erhöht? Was passiert mit “Berlin”, wenn man den Fakten-Head deaktiviert?
3.3 Eigene Experimente (JSON)
Für weitere Experimente ist das System offen gestaltet. Neue Szenarien können einfach über eine JSON-Struktur definiert werden. Dies ermöglicht es, eigene Prompts zu testen und festzulegen, welche Tokens welche Attention-Heads triggern sollen. So lässt sich der Explorer vom reinen Lern-Tool zu einer individuellen Testumgebung erweitern. Anleitungen zur JSON-Struktur finden sich in der Dokumentation des Tools.
4. Ausblick: Der Beginn der Pipeline
Die wissenschaftlichen Herausforderungen sind nun klar identifiziert. Wir stehen vor zwei fundamentalen Problemen, die die Architektur lösen muss: Wie unterscheiden wir Bedeutungen (Bank vs. Bank)? Und wie steuern wir den Kontext (Berlin vs. Bonn)?
Klassische Erklärungen zur Transformer-Architektur enden oft dort, wo das echte Verständnis beginnen sollte: bei der Frage, warum das Modell in einem konkreten Fall so und nicht anders reagiert. Der LLM Explorer kehrt diese Logik um: Statt Theorie zu beschreiben und auf Verständnis zu hoffen, erlaubt er es, Hypothesen direkt zu testen. Was geschieht, wenn der “Fakten-Head” schweigt? Welche latenten Bedeutungen werden sichtbar, wenn dominante Pfade unterdrückt werden? Diese Fragen lassen sich nicht durch Lesen beantworten – nur durch Ausprobieren.
Genau das ist das Ziel dieser Serie. In den kommenden Artikeln werden wir diese Fragen nicht nur theoretisch beantworten, sondern mithilfe des LLM Explorers praktisch lösen. Er wird dabei unser ständiger Begleiter sein. Wir werden uns anschauen, wie man die spezifischen Regler im LLM Explorer bedient, um den Kontext-Mixer und die dreifache Bank live zu manipulieren und die Theorie überprüfbar zu machen.
Die Antwort auf die linguistischen Rätsel liegt in der schrittweisen Transformation der Sprache. Doch bevor das Modell “verstehen” kann, muss es “lesen”. Im nächsten Artikel (Teil 2) widmen wir uns daher der Phase 0 (Tokenization) der Architektur.
Wir werden sehen, warum der Computer das Wort “Bank” gar nicht als Wort sieht, sondern als eine Zahl (z.B. ID 4115), und wir werden das fundamentale Problem aufdecken, das entsteht, wenn ein Satz nur noch aus einer Liste von Zahlenwerten besteht. Dort beginnt die Reise durch die Pipeline.
Weblinks
References
- (2023): Attention Is All You Need. 2023.
- (2020): Language Models are Few-Shot Learners. 2020.
- (2013): Efficient Estimation of Word Representations in Vector Space. 2013.